
The Robots Exclusion Standard was developed in 1994 so that website owners can advise search engines how to crawl your website. It works in a similar way as the robots meta tag which I discussed in great length recently. The main difference being that the robots.txt file will stop search engines from seeing a page or directory, whereas the robots meta tag only controls whether it is indexed.
Placing a robots.txt file in the root of your domain lets you stop search engines indexing sensitive files and directories. For example, you could stop a search engine from crawling your images folder or from indexing a PDF file that is located in a secret folder.
Major searches will follow the rules that you set. Be aware, however, that the rules you define in your robots.txt file cannot be enforced. Crawlers for malicious software and poor search engines might not comply with your rules and index whatever they want. Thankfully, major search engines follow the standard, including Google, Bing, Yandex, Ask, and Baidu.
In this article, I would like to show you how to create a robots.txt file and show you what files and directories you may want to hide from search engines for a WordPress website.
- 1 The Basic Rules of the Robots Exclusion Standard
- 2 Non Standard Robots.txt Rules
- 3 Advanced Robots.txt Techniques
- 4 Commenting Your Robots.txt Code
- 5 What to Place in a WordPress Robots.txt File
- 6 What to Place in Your Robots.txt File
- 7 The Maximum Size of a Robots.txt File
- 8 Testing Your Robots.txt File
- 9 Final Thoughts
The Basic Rules of the Robots Exclusion Standard
A robots.txt file can be created in seconds. All you have to do is open up a text editor and save a blank file as robots.txt. Once you have added some rules to the file, save the file and upload it to the root of your domain i.e. www.yourwebsite.com/robots.txt. Please ensure you upload robots.txt to the root of your domain; even if WordPress is installed in a subdirectory.
I recommend file permissions of 644 for the file. Most hosting setups will set up that file with those permissions after you upload the file. You should also check out the WordPress plugin WP Robots Txt; which allows you to modify the robots.txt file directly through the WordPress admin area. It will save you from having to re-upload your robots.txt file via FTP every time you modify it.
Search engines will look for a robots.txt file at the root of your domain whenever they crawl your website. Please note that a separate robots.txt file will need to be configured for each subdomain and for other protocols such as https://www.yourwebsite.com.
It does not take long to get a full understanding of the robots exclusion standard, as there are only a few rules to learn. These rules are usually referred to as directives.
The two main directives of the standard are:
- User-agent – Defines the search engine that a rule applies to
- Disallow – Advises a search engine not to crawl and index a file, page, or directory
An asterisk (*) can be used as a wildcard with User-agent to refer to all search engines. For example, you could add the following to your website robots.txt file to block search engines from crawling your whole website.
User-agent: * Disallow: /
The above directive is useful if you are developing a new website and do not want search engines to index your incomplete website.
Some websites use the disallow directive without a forward slash to state that a website can be crawled. This allows search engines complete access to your website.
The following code states that all search engines can crawl your website. There is no reason to enter this code on its own in a robots.txt file, as search engines will crawl your website even if you do not define add this code to your robots.txt file. However, it can be used at the end of a robots.txt file to refer to all other user agents.
User-agent: * Disallow:
You can see in the example below that I have specified the images folder using /images/ and not www.yourwebsite.com/images/. This is because robots.txt uses relative paths, not absolute URL paths. The forward slash (/) refers to the root of a domain and therefore applies rules to your whole website. Paths are case sensitive, so be sure to use the correct case when defining files, pages, and directories.
User-agent: * Disallow: /images/
In order to define directives for specific search engines, you need to know the name of the search engine spider (aka the user agent). Googlebot-Image, for example, will define rules for the Google Images spider.
User-agent: Googlebot-Image Disallow: /images/
Please note that if you are defining specific user agents, it is important to list them at the start of your robots.txt file. You can then use User-agent: * at the end to match any user agents that were not defined explicitly.
It is not always search engines that crawl your website; which is why the term user agent, robot, or bot, is frequently used instead of the term crawler. The number of internet bots that can potentially crawl your website is huge. The website Bots vs Browsers currently lists around 1.4 million user agents in its database and this number continues to grow every day. The list contains browsers, gaming devices, operating systems, bots, and more.
Bots vs Browsers is a useful reference for checking the details of a user agent that you have never heard of before. You can also reference User-Agents.org and User Agent String. Thankfully, you do not need to remember a long list of user agents and search engine crawlers. You just need to know the names of bots and crawlers that you want to apply specific rules to; and use the * wildcard to apply rules to all search engines for everything else.
Below are some common search engine spiders that you may want to use:
- Bingbot – Bing
- Googlebot – Google
- Googlebot-Image – Google Images
- Googlebot-News – Google News
- Teoma – Ask
Please note that Google Analytics does not natively show search engine crawling traffic as search engine robots do not activate Javascript. However, Google Analytics can be configured to show information about the search engine robots that crawl your website. Log file analyzers that are provided by most hosting companies, such as Webalizer and AWStats, do show information about crawlers. I recommend reviewing these stats for your website to get a better idea of how search engines are interacting with your website content.
Non Standard Robots.txt Rules
User-agent and Disallow are supported by all crawlers, though a few more directives are available. These are known as non-standard as they are not supported by all crawlers. However, in practice, most major search engines support these directives too.
- Allow – Advises a search engine that it can index a file or directory
- Sitemap – Defines the location of your website sitemap
- Crawl-delay – Defines the number of seconds between requests to your server
- Host – Advises the search engine of your preferred domain if you are using mirrors
It is not necessary to use the allow directive to advise a search engine to crawl your website, as it will do that by default. However, the rule is useful in certain situations. For example, you can define a directive that blocks all search engines from crawling your website, but allow a specific search engine, such as Bing, to crawl. You could also use the directive to allow crawling of a particular file or directory; even if the rest of your website is blocked.
User-agent: Googlebot-Image Disallow: /images/ Allow: /images/background-images/ Allow: /images/logo.png
Please note that this code:
User-agent: * Allow: /
Produces the same outcome as this code:
User-agent: * Disallow:
As I mentioned previously, you would never use the allow directive to advise a search engine to crawl a website as it does that by default.
Interestingly, the allow directive was first mentioned in a draft of robots.txt in 1996, but was not adopted by most search engines until several years later.
Ask.com uses “Disallow:” to allow crawling of certain directories. While Google and Bing both take advantage of the allow directive to ensure that certain areas of their websites are still crawlable. If you view their robots.txt files, you can see that the allow directive is always used for subdirectories and files and pages under directories that are hidden. As such, the allow directive should be used in conjunction with the disallow rule.
User-agent: Bingbot Disallow: /files Allow: /files/eBook-subscribe.pdf/
Multiple directives can be defined for the same user agent. Therefore, you can expand your robots.txt file to specify a large number of directives. It just depends on how specific you want to be about what search engines can and cannot do (note that there is a limit to how many lines you can add, but I will speak about this later).
Defining your sitemap will help search engines locate your sitemaps quicker. This, in turn, helps them locate your website content and index it. You can use the Sitemap directive to define multiple sitemaps in your robots.txt file.
Note that it is not necessary to define a user agent when you specify where your sitemaps are located. Also bear in mind that your sitemap should support the rules you specify in your robots.txt file. That is, there is no point listing pages in your sitemap for crawling if your robots.txt file disallows crawling of those pages.
A sitemap can be placed anywhere in your sitemap. Generally, website owners list their sitemap at the beginning or near the end of the robots.txt file.
Sitemap: http://www.yourwebsite.com/sitemap_index.xml Sitemap: http://www.yourwebsite.com/category-sitemap.xml Sitemap: http://www.yourwebsite.com/page-sitemap.xml Sitemap: http://www.yourwebsite.com/post-sitemap.xml Sitemap: http://www.yourwebsite.com/forum-sitemap.xml Sitemap: http://www.yourwebsite.com/topic-sitemap.xml Sitemap: http://www.yourwebsite.com/post_tag-sitemap.xml
Some search engines support the crawl delay directive. This allows you to dictate the number of seconds between requests on your server, for a specific user agent.
User-agent: teoma Crawl-delay: 15
Note that Google does not support the crawl delay directive. To change the crawl rate of Google’s spiders, you need to log in to Google Webmaster Tools and click on Site Settings.
Webmaster Tools Site Settings can be selected via the cog icon.
You will then be able to change the crawl delay from 500 seconds to 0.5 seconds. There is no way to enter a value directly; you need to choose the crawl rate by sliding a selector. Additionally, there is no way to set different crawl rates for each Google spider. For example, you cannot define one crawl rate for Google Images and another for Google News. The rate you set is used for all Google crawlers.
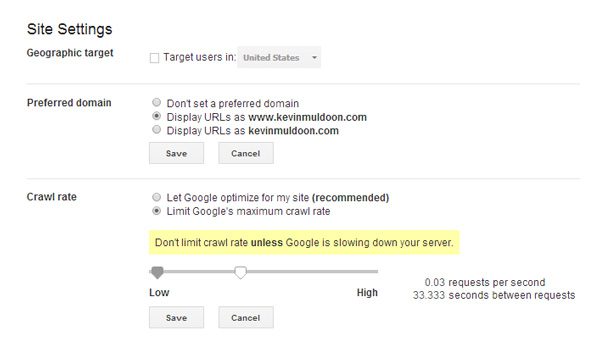
Unfortunately, one crawl rate is applied to all search engine crawlers.
A few search engines, including Google and the Russian search engine Yandex, let you use the host directive. This allows a website with multiple mirrors to define the preferred domain. This is particularly useful for large websites that have set up mirrors to handle large bandwidth requirements due to downloads and media.
I have never used the host directive on a website myself, but apparently you need to place it at the bottom of your robots.txt file after the crawl delay directive. Remember to do this if you use the directive in your website robots.txt file.
Host: www.mypreferredwebsite.com
As you can see, the rules of the robots exclusion standard are straight forward. Be aware that if the rules you set out in your robots.txt file conflict with the rules you define using a robots meta tag; the more restrictive rule will be applied by the search engine. This is something I spoke about recently in my post “How To Stop Search Engines From Indexing Specific Posts And Pages In WordPress“.
Advanced Robots.txt Techniques
The larger search engines, such as Google and Bing, support the use of wildcards in robots.txt. These are very useful for denoting files of the same type.
An asterisk (*) can be used to match occurrences of a sequence. For example, the following code will blog a range of images that have logo at the beginning.
User-agent: * Disallow: /images/logo*.jpg
The code above would disallow images within the images folder such as logo.jpg, logo1.jpg, logo2.jpg. logonew.jpg, and logo-old.jpg.
Be aware that the asterisk will do nothing if it is placed at the end of a rule. For example, Disallow: about.html* is the same as Disallow: about.html. You could, however, use the code below to block content in any directory that starts with the word test. This would hide directories named test, testsite, test-123 etc.
User-agent: * Disallow: /test*/
Wildcards are useful for stopping search engines from crawling files of a particular type or pages that have a specific prefix.
For example, to stop search engines from crawling all of your PDF documents within your downloads folder, you could use this code:
User-agent: * Disallow: /downloads/*.pdf
And you could stop search engines from crawling your wp-admin, wp-includes, and wp-content directories, by using this code:
User-agent: * Disallow: /wp-*/
Wildcards can be used in multiple locations in a directive. In the example below, you can see that I have used a wildcard to denote any image that begins with holiday. I have replaced the year and month directory names with wildcards so that any image is included; regardless of the month and year it was uploaded.
User-agent: * Disallow: /wp-content/uploads/*/*/holiday*.jpg
You can also use wildcards to refer to part of the URL that contains a certain character or series of characters. For example, you can block any URL that contains a questions mark (?) by using this code:
User-agent: * Disallow: /*?*
The following command would stop search engines from crawling any URL that begins with a quote:
User-agent: * Disallow: /"
One thing that I have not touched upon until now is that robots.txt uses prefix matching. What this means is that using Disallow: /dir/ would block search engines from a directory named /dir/ and from directories such as /dir/directory2/, /dir/test.html, etc.
This also applies to file names. Consider the following command for robots.txt:
User-agent: * Disallow: /page.php
As you know, the above code would stop search engines from crawling page.php. However, it would also stop search engines from crawling /page.php?id=25 and /page.php?id=2&ref=google. In short, robots.txt will block any extension to the URL you block. So blocking www.yourwebsite.com/123 will also block www.yourwebsite.com/123456 and www.yourwebsite.com/123abc.
In many cases, this is the desired effect; however it is sometimes better to specify the end of a path so that no other URL’s are affected. To do this, you can use the dollar sign ($) wildcard. It is frequently used when a website owner wants to block a particular type of file type.
In my previous example of blocking page.php, we can ensure that only page.php is blocked by adding the $ wildcard at the end of the rule.
User-agent: * Disallow: /page.php$
And we can use it to ensure that only the /dir/ directory is blocked, not /dir/directory2/ or /dir/test.html.
User-agent: * Disallow: /dir/$
A lot of website owners use the $ wildcard to specify what types of images Google Images can crawl:
User-agent: Googlebot-Image Disallow: Allow: /*.gif$ Allow: /*.png$ Allow: /*.jpeg$ Allow: /*.jpg$ Allow: /*.ico$ Allow: /*.jpg$ Allow: /images/
My previous examples of blocking PDF and JPG files did not use a $ wildcard. I have always been under the impression that it was not necessary to use it, as something like a PDF, Word document, or image file, is not going to have any suffix to the URL. That is, .pdf, .doc, or .png, would be the absolute end of the URL.
However, for many website owners, it is common practice to attach the $ wildcard. During my research for this article, I was unable to find any documentation that states why this is necessary. If you any of you are aware of the technical reason for doing it, please let me know and I will update this article 🙂
Be aware that wildcards are not supported by all crawlers, therefore you may find that some search engines will not comply with the rules you define. Search engines that do not support wildcards will treat * as if its a character you want to allow or disallow.
Google, Bing and Ask, do actively support wildcards. And if you view the Google robots.txt file, you will see that Google use wildcards themselves.
Commenting Your Robots.txt Code
It is in your best interest to get into the habit of documenting the code in your robots.txt file. This will help you quickly understand the rules you have added when you refer to it later.
You can publish comments in your robots.txt file using the hash symbol #:
# Block Google Images from crawling the images folder User-agent: Googlebot-Image Disallow: /images/
A comment can be placed at the start of a line or after a directive:
User-agent: Googlebot-Image # The Google Images crawler Disallow: /images/ # Hide the images folder
I encourage you to get into the habit of commenting your robots.txt file from the start as it will help you understand the rules you create when you review the file at a later date.
What to Place in a WordPress Robots.txt File
The great thing about the robots exclusion standard is that you can view the robots.txt file of any website on the internet (as long as they have uploaded one). All you have to do is visit www.websitename.com/robots.txt.
If you check out the robots.txt file of some WordPress websites, you will see that website owners define different rules for search engines.
Elegant Themes currently uses the following code in their robots.txt file:
User-agent: * Disallow: /preview/ Disallow: /api/ Disallow: /hostgator
As you can see, Elegant Themes just blocks three directories from being crawled and indexed.
WordPress co-founder Matt Mullenweg uses the following code on his personal blog:
User-agent: * Disallow: User-agent: Mediapartners-Google* Disallow: User-agent: * Disallow: /dropbox Disallow: /contact Disallow: /blog/wp-login.php Disallow: /blog/wp-admin
Matt blocks a dropbox folder and a contact folder. He also blocks the WordPress login page and the WordPress admin area.
WordPress.org has the following in their robots.txt file:
User-agent: * Disallow: /search Disallow: /support/search.php Disallow: /extend/plugins/search.php Disallow: /plugins/search.php Disallow: /extend/themes/search.php Disallow: /themes/search.php Disallow: /support/rss Disallow: /archive/
Eight different rules are defined in WordPress.org’s robots.txt file and six of these rules refer to search pages. Their RSS page is also hidden, as is an archive page that does not even exist (which suggests it has not been updated in years).
The most interesting thing about the WordPress.org robots.txt file is that it does not follow the suggestions they advise for adding to a robots.txt file. They advise the following :
Sitemap: http://www.example.com/sitemap.xml # Google Image User-agent: Googlebot-Image Disallow: Allow: /* # Google AdSense User-agent: Mediapartners-Google Disallow: # digg mirror User-agent: duggmirror Disallow: / # global User-agent: * Disallow: /cgi-bin/ Disallow: /wp-admin/ Disallow: /wp-includes/ Disallow: /wp-content/cache/ Disallow: /trackback/ Disallow: /feed/ Disallow: /comments/ Disallow: /category/*/* Disallow: */trackback/ Disallow: */feed/ Disallow: */comments/ Disallow: /*? Allow: /wp-content/uploads/
The above code has been reproduced on thousands of blogs as the best rules to add to your robots.txt file. The code was originally published on WordPress.org several years ago and has remained unchanged. The fact that the suggested code disallows the spider of Digg illustrates how old it is (it is, afterall, several years since anyone worried about “The Digg Effect“).
However, the principles of the robots exclusion standard have not changed since the page was first published. It is still recommended that you stop search engines from crawling important directories such as wp-admin, wp-includes, and your plugin, themes, and cache directories. It is best to hide your cgi-bin and your RSS feed too.
Yoast noted in an article two years ago that it is better not to hide your website feed as it acts as a sitemap for Google.
“Blocking /feed/ is a bad idea because an RSS feed is actually a valid sitemap for Google. Blocking it would prevent Google from using that to find new content on your site.” – Yoast
As Jeff Starr correctly pointed out, you do not need to use the RSS feed as a sitemap if you have a functioning sitemap on your website already.
“Sure that makes sense if you don’t have a sitemap 😉 Otherwise, keeping your feed content out of search results keeps juice focused on your actual web pages.” – Jeff Starr
Yoast takes a minimal approach to robots.txt file. Two years ago, he suggested the following to WordPress users:
User-Agent: * Disallow: /wp-content/plugins/
His current robots.txt file has a few additional lines, though by and large it remains the same as the one he previously suggested. Yoast’s minimal approach stems from his belief that many important pages should instead be hidden from search engine results by using a <meta name=”robots” content=”noindex, follow”> tag.
WordPress developer Jeff Starr, author of the amazing Digging Into WordPress, takes a different approach.
His current robots.txt file looks like this:
User-agent: * Disallow: /wp-admin/ Disallow: /wp-content/ Disallow: /wp-includes/ Disallow: /comment-page- Disallow: /trackback/ Disallow: /xmlrpc.php Disallow: /blackhole/ Disallow: /mint/ Disallow: /feed/ Allow: /tag/mint/ Allow: /tag/feed/ Allow: /wp-content/images/ Allow: /wp-content/online/ Sitemap: http://perishablepress.com/sitemap.xml
In addition to blocking wp-admin, wp-content, and wp-includes; Jeff stops search engines from seeing trackbacks and the WordPress xmlrpc.php (a file that lets you publish articles to your blog via blog a client).
Comment pages are also blocked. If you don’t break your pages into comments, then you may want to consider blocking additional comment pages too.
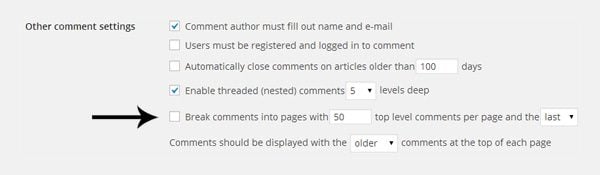
The option to break comments into pages can be found in your WordPress discussion settings i.e. www.yourwebsite.com/wp-admin/options-discussion.php.
Jeff also stops crawlers from seeing his RSS feed, a blackhole directory he set up for bad bots, and a private directory named mint. Jeff makes a point of allowing tags for mint and feed to be seen, as well as his images and a directory named online that he uses for demos and scripts. Lastly, Jeff defines the location of his sitemap for search engines.
What to Place in Your Robots.txt File
I know that many of you are reading this article who simply want the code to place in your robots.txt file and move on. However, it is important that you understand the rules that you specify for search engines. It is also important to recognise that there is no agreed upon standard on what to place in the robots.txt file.
We have seen this above with the different approaches of WordPress developer Jeff Starr and Joost de Valk (AKA Yoast); two people who are rightfully recognised as WordPress experts. We have also seen that the advice given on WordPress.org has not been updated in several years and their own robots.txt file does not follow their own suggestion; instead focusing on blocking search functionality.
I have changed the contents of my blog’s robots.txt files many times over the years. My current robots.txt file took inspiration from Jeff Starr’s robots.txt suggestions, AskApache’s suggestions, and advice from several other developers that I respect and trust.
At the moment, my robots.txt file looks like this:
# Disallowed and allowed directories and files User-agent: * Disallow: /wp-admin/ Disallow: /wp-content/ Disallow: /wp-includes/ Disallow: /comment-page- Disallow: /trackback/ Disallow: /xmlrpc.php Disallow: /feed/ Allow: /wp-content/uploads/ # Define website sitemaps Sitemap: http://www.kevinmuldoon.com/sitemap_index.xml Sitemap: http://www.kevinmuldoon.com/post-sitemap.xml Sitemap: http://www.kevinmuldoon.com/page-sitemap.xml Sitemap: http://www.kevinmuldoon.com/category-sitemap.xml Sitemap: http://www.kevinmuldoon.com/author-sitemap.xml
My robots.txt file stops search engines from crawling the important directories that I discussed earlier. I also make a point of allowing crawling of my uploads folder so that images can get indexed.
I have always considered the code in my robots.txt file flexible. If new information arises that shows that I should change the code I am using, I will happily modify the file. Likewise, if I add new directories to my website or find that a page or directory is being incorrectly indexed, I will modify the file. The key is to evolve the robots.txt file as and when needed.
I encourage you to choose one of the above examples of robots.txt for your own website and then change it accordingly for your own website. Remember, it is important that you understand all the directives that you add to your robots.txt file. The Robots Exclusion Standard can be used to stop search engines crawling files and directories that you do not want indexed, however if you enter the wrong code, you may end up blocking important pages from being crawled.
The Maximum Size of a Robots.txt File
According to an article on AskApache, you should never use more use more than 200 disallow lines in your robots.txt file. Unfortunately, they do not provide any evidence in the article that states why this is the case.
In 2006, some members of Webmaster World reported seeing a message from Google that the robots.txt file should be no more than 5,000 characters. This would probably work out to be around 200 lines if we assume an average of 25 characters per line; which is probably where AskApache got this figure of 200 disallow lines from
Google’s John Mueller clarified the issue a few years later. On Google+, he said:
“If you have a giant robots.txt file, remember that Googlebot will only read the first 500kB. If your robots.txt is longer, it can result in a line being truncated in an unwanted way. The simple solution is to limit your robots.txt files to a reasonable size.”
Be sure to check the size of your robots.txt file if it has a couple of hundred lines of text. If the file is larger than 500kb, you will have to reduce the size of the file or you may end up with an incomplete rule being applied.
Testing Your Robots.txt File
There are a number of ways in which you can test your robots.txt file. One option is to use the Blocked URLs feature, which can be found under the Crawl section in Google Webmaster Tools.
Log in to Google Webmaster Tools.
The tool will display the contents of your website’s robots.txt file. The code that is displayed comes from the last copy of robots.txt that Google retrieved from your website. Therefore, if you updated your robots.txt file since then, the current version might not be displayed. Thankfully, you can enter any code you want into the box. This allows you to test new robots.txt rules, though remember that this is only for testing purposes i.e. you still need to update your actual website robots.txt file.
You can test your robots.txt code against any URL you wish. The Googlebot crawler is used to test your robots.txt file by default. However, you can also choose from four other user agents. This includes Google-Mobile, Google-Image, Mediapartners-Google (Adsense), and Adsbot-Google (Adwords).
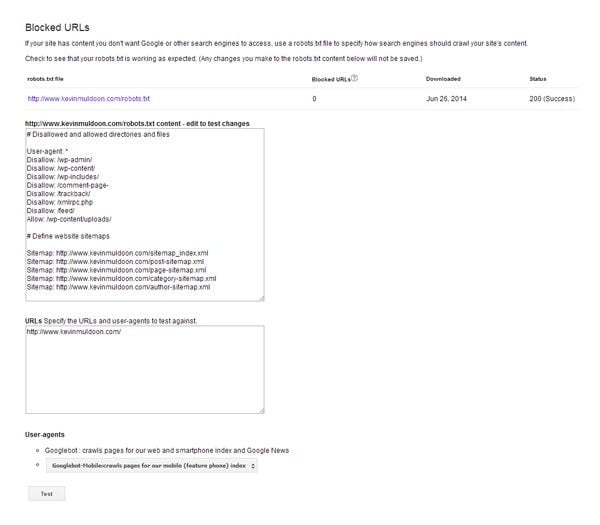
The Blocked URLs took is useful for testing different robots.txt rules.
The results will highlight any errors in your robots.txt file; such as linking to a sitemap that does not exist. It is a great way of seeing any mistakes that need correcting.
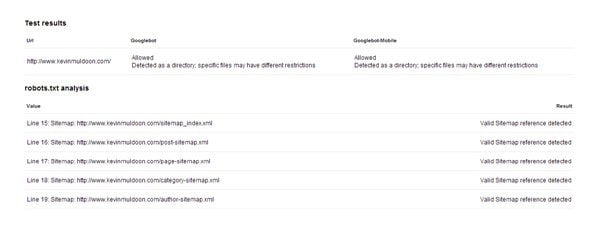
Check the results of your robots.txt file to see if anything needs changed.
Another useful tool is the Frobee Robots.txt Checker. It will highlight any errors that are found and show if there any restrictions on access.
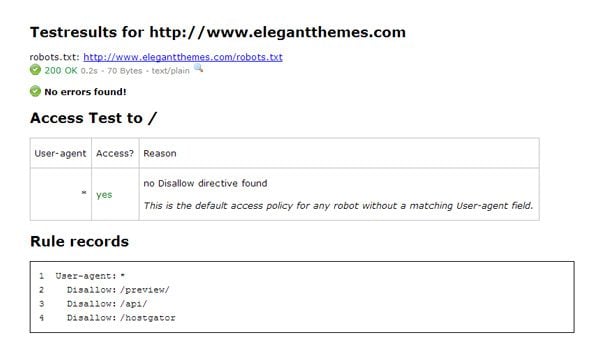
Frobee’s Robots.txt Checker is quick and eays to use.
Another robots.txt analyzer I like can be found on Motoricerca. It will highlight any commands that you have entered that are not supported or not configured correctly.
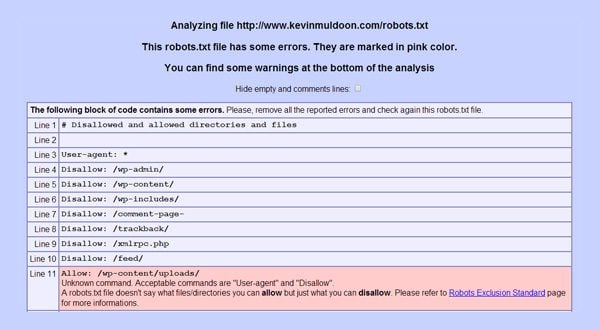
A user friendly robots.txt checker that checks every line of your robots.txt file.
It is important to check the code in your robots.txt file using a robots.txt analyzer before you add the code to your website robots.txt file. This will ensure that you have not entered any lines incorrectly.
Final Thoughts
The Robots Exclusion Standard is a powerful tool for advising search engines what to crawl and what not to crawl. It does not take long to understand the basics of creating a robots.txt file, however if you need to block a series of URL’s using wildcards, it can get a little confusing. So be sure to use a robots.txt analyzer to ensure that the rules have been set up in the way that you want them.
Also remember to upload robots.txt to the root of your directory and be sure to adjust the code in your own robots.txt file accordingly if WordPress has been installed in a subdirectory. For example, if you installed WordPress at www.yourwebsite.com/blog/, you would disallow the path /blog/wp-admin/ instead of /wp-admin/.
You may be surprised to hear that search engines can still list a blocked URL if other websites link to that page. Matt Cutts explains how this can occur in the video below:
I hope you have found this tutorial on creating a robots.txt file for your website useful. I recommend creating a robots.txt file for your own website and test the results through an analyzer to help you get a feel for how things work. Practice makes perfect 🙂
Should you want to learn more about creating and editing a robots.txt file, I recommend checking out the following resources for further reading:
- Robots Exclusion Standard (Wikipedia)
- Better Robots.txt Rules for WordPress (Jeff Starr)
- WordPress robots.txt Example (Yoast)
- Updated robots.txt for WordPress (AskApache)
- Robots.txt Optimization (WordPress.org)
- Robots.txt Specifications (Google)
- Improving on Robots Exclusion Protocol (Google)
- How to Create a Robots.txt file (Bing)
- The Web Robots Pages (Useful website, however it has not been updated since 2007)
- Learn About Robots.txt with Interactive Examples (MOZ)
- About Search Indexing Robots and Spiders (Search Tools)
Last but not least, be sure to subscribe to the Elegant Themes blog in order to get updates of our latest articles 🙂
Article thumbnail image by grop / shutterstock.com


Hey, so heplfull and finally all the wildcarts explained, that’s really nice 🙂
1. I have one question and not sure so far.
How robots.txt should looks when I want start only blog crawling without main site which is during the building and changes.
Example like below is ok or google will be confused with this?:
User-agent: *
Disallow: /
Allow: /blog
Googbox is capable of finding matching text inside thousands of files and get you the link to download it. Search can be done with regular expressions, include or exclude certain search patterns. http://www.googbox.com is capable of searching within folders and subfolders. Search is performed on the server, hence it will not affect your PC / Laptops performance.
Google keeps telling me they can’t index my website. I should fix this somehow.
My website is just two pages. There is nothing in it I do not want indexed. I have tried a blank robots.txt file in my root directory, and I have tried deleting the robots.txt. Nothing works. Google keeps telling me I have to do something.
What could be wrong? Is there something about the specs in my index file? I have not changed this for years.
Your advice will be greatly appreciated!
last checked perishable dont block wp-content…
In 2015 the wordpress robots.txt should only disallow robots.txt according to yoast, due to new algorithmic updates done by Google. However I found that yoast seo plugin does not create the robots.txt file automatically as soon as plugin is installed. One have to manually go to file editor option and check the robots.txt and htaccess files, this way wordpress triggers to create a robots.txt file. It should be noted that latest search console is considering robots.txt as very important. Google bot now makes decision to crawl the websites based on rules and robots.txt accessibility. This blog would guide anyone on how to set the robots.txt file correctly. thanks for sharing this. 🙂
Hello Kevin
my google webmaster tool suddenly showing soft 404 error too much . error is
http://www.sample.com/search/page/1/
http://www.sample.com/search/page/2/
…………………………………………………
————————————————
http://www.sample.com/search/page/80/
i have created 404 error page but in search type (page/*) 404 page not coming . i am using WordPress . i have checked many website in this search term they are also not gating 404 page .
what should i do … please help meeee please
Great post! I’d like to point out for those who might be visiting this page now that Google’s new Mobile standards have changed things somewhat, especially when it comes to blocking the /themes/ folder. Since Google now renders pages, and wants to see they are mobile friendly, blocking the /wp-content/themes/ folder can create problems–and cause your site to not be seen as mobile-friendly. Yoast now basically doesn’t list anything on their robots.txt, see this new article:
https://yoast.com/wordpress-robots-txt-example/
One other thing I would point out in regards to the length of a robots.txt. I would argue that the 200 line maximum is FALSE. My reason for saying this? Go straight to the horse’s mouth: http://www.google.com/robots.txt. As of this writing, their file is 320 lines long. It’s still under 500kb, though, so that rule might be valid.
This is one of the nicest post about doing the robots.txt file for your blog.
Kudos!
I’ve been blogging for 4 years now, however, i have only recently found the Robot.txt setting.
I’ve searched for hours and have a small understanding of how to use it, so i’ve written some code and it says its enabled. Is this correct? I’m worried it’s going to effect my views.
I’ve copied it exactly how it is on the site, spaces included.
User-agent: Mediapartners-Google:
Disallow:
User-agent: *
Disallow:
Allow:/
Sitemap:http://creativefitnesschannel.blogspot.co.uk/atom.xml?redirect=false&start-index=1&max-results=100
Hi, I am a new blogger, one month old. My blog url is http://www.objectivebooks.com. Recently (on 29th Jan)I had made a big mistake while changing the custom robots.txt file. As I don’t have any html knowledge, so I just searched it in google and in that field, instead of my own domain, by mistake I din’t edit the lines copied from some other site, and uploded that information to my blogs robot.txt editor and saved and submitted the sitemat too to google webmaster.
Sitemap: http://xxxxxxx.blogspot.in/atom.xml?redirect=false&start-index=1&max-results=500
After submitting the sitemap to google webmaster, from that day itself, my traffic became ‘Zero’ while previously, it was average 100 visitor per day.
The ‘fetch as google’ also showing page not found for all my post links.
But yesterday, I came to know from google help forum that it is not necessary to enable the robot.txt. So I just disabled it. But still my site visitor is zero and fetch as google search result is also same.
I have submitted my sitemap to bing too, but there I did not make any mistake.
I am really very much worry about it, and it disappointed me a lot as I am not getting what to do or how to fix,if there is any problem. Please help me out of this problem. please please please, For this I will be ever grateful to you.
This is a great post
Question… Has anyone at Elegant Themes written a blog post or guide to optimizing sites, not the SEO stuff likes tags, and content and the things that change and such, but more like :
how not to use inline styles
combining CSS file
Minify CSS
Minify JavaScript
Eliminate render-blocking JavaScript and CSS in above-the-fold content
Optimize images
Media Queries
Mobile App Shortcut
Site Maps and where to put. (you of course..)
Meta Viewport Tag
Apple Icon
Mobile redirection
Reduce server response time
Leverage browser caching
schema.org
email address onpage
Anyway, some the items I listed are repeats, but pulled from two page analysis tools we use looking over our sites which some use your themes. The themes always have these indicators as issues needing to be optimized. I’m working my way through a completely “optimized” site. That being subjective at best. But with some items that are simple…
Let me and your readers know how we should go about setting that stuff up better! Make it into a challenge for first 1/2 of 2015! I pretty sure most of your customers would enjoy the topic! I ran through a couple sites in the showcase and with a quick analysis, they too have the same common factors on them, same as mine!
Just a thought…
Best, Evan
hi there, i have a question. i bought an old domain from auction and after i setup the website, i published many posts. Now as because it’s old domain google has iindexed many of it’s old post’s / articles which no more exists. So i went to webmaster tools and removed those URL’s. but the problem is, after i removed the url after few hours it was removed, but 1-2 day a new link was indexed whoich also no more exists….can u please tell me what’s going on ????
Nice article!! editing robot.txt via webmaster tools is the most easiest method and I always prefer it. Thanks for sharing with us. 🙂
Nice post and very simple topic too.
But, this is good that you are taking care of newbies and posting about such small,simple but, most important things.
A proper robots.txt file is very necessary for better search engine crawling and blocking any bot if we want.
Thanks for sharing with us.
Hello Admin. Pls, I just found out that my blog (http://campuslink.com.ng) doesnt have a Robot.txt file. Do I just create a Robot.txt file and upload to my public Html or do you really Recommend the use of Plugin as in your post?
Thanks as you reply. Have a Blessed weekend.
Indepth guide, Thanks for the lovely article. It very essential to have effective Robots.txt file
Is there any security risk in detailing what you don’t want indexed in a public text file in the root of your domain?
Obviously one should turn off directory browsing, and restrict access to private folders.
If the folder or contents are never publicly linked to, is there any way for search engines to discover and index these folders?
Thanks for the awesome tutorial!
Hi, thanks for the article, it is well written, good job.
Few questions to this topic:
1) should the robots.txt remain visible? Isn’t there any security risk with that? Or they should be blocked with .htaccess?
2) If this file is “hidden” with .htaccess, can it sill be discovered by crawlers? I assume if it’s hidden, it won’t be even visible to crawlers.
Thank you!
D.
You should write also on: How CORRECTLY To Set Up CHMOD Permissions For Your WordPress Website after fresh installation !
Chinese spambots? or block a country?
You know, when I saw this come in I wasn’t going to bother. Yeah Boring Robots.TXT Like I’d need to know anything more than allow all..
But kept it for those what to do next moments.
WoW! I had no freaking idea how many options boring robots.txt had.
Great Post Kev!
This article is very informative and totally awesome! I love Elegant Themes :-*
Nice & comprehensive article. Thanks.
Personally, I found Yandex and Baidu to behave badly. When I blocked their IPs in Russia and China, they came via the US & Japan.
To get rid of them properly/forever, as well as the other 300 odd bad bots, I had to use Incapsula.com as a proxy. Cloudflare doesn’t do this- to them all search bots are welcome.
If you don’t have a massive server, it is easy to squeeze more capacity/performance from your site by getting rid of the useless bots.
Google and rest of its services are blocked in china . The only way to make your website visible to 1.4 Billion Chinese users, is to allow Baidu to index your site.
Why do see Yandex as “bad bot”??? Is this the traditional cold war ignorance? Russia and China are so bad?
Do not forget that there are more people living in Russia than in the USA for example and they are not evil monsters-
Yandex is a very good service and very often it has better results than Google, if you check their website, you will see how many helpful services they offer
you couldn’t go by car in Moscow without their traffic jam information, for example
stop seeing the world through your small-angle-lens, please!
A case of Copernicus Complex in Americans!
That is a very comprehensive post. thanks as it was a nice refresh of many things I have forgotten.
Cheers
Dwight
Are there any news on any new theme?
Yep, we recently announced “Extra.” You can read more about it (and all of our other upcoming products) in our Sneak Peeks Category.
yes i saw that. but you released more theme in the past